Stuff - mainly geek, a little diabetes, some rant. Possibly all three in the same post. Basically anything I find interesting and/or worth sharing.
These are my personal views, unless I've been hacked.
The event keyword is a great example of syntactic sugar. The following class definition
public class Button
{
public event EventHandler Pushed;
}
results in the following code being generated
public class Button
{
private EventHandler _pushed;
public event EventHandler Pushed
{
add
{
EventHandler eventHandler = this._pushed;
EventHandler comparand;
do
{
comparand = eventHandler;
eventHandler = System.Threading.Interlocked.CompareExchange<EventHandler>(ref this._pushed, comparand + value, comparand);
}
while (eventHandler != comparand);
}
remove
{
EventHandler eventHandler = this._pushed;
EventHandler comparand;
do
{
comparand = eventHandler;
eventHandler = System.Threading.Interlocked.CompareExchange<EventHandler>(ref this._pushed, comparand - value, comparand);
}
while (eventHandler != comparand);
}
}
}
In .Net, an event is a special type of multicast delegate which can only be invoked from the class or struct where it is declared. Any number of subscriptions can be added to the event, which will be called in order when the event is raised.
The add and remove blocks that manage event subscriptions are generally auto-implemented, but they can easily be overridden. As you can see from the code above, the compiler-implemented code uses the System.Threading.Interlocked.CompareExchange method to guarantee thread safety around the adding and removing of subscriptions.
The C# using statement (as opposed to the using directive) is usually described along the lines of syntactic sugar for a try/finally block that guarantees to call the Dispose method of a class or struct that implements IDisposable. This is correct except for a subtle detail that I'll explain in a while.
Consider the following code:
using System;
public class Program
{
public static void Main(string[] args)
{
using (var myDisposable = new MyDisposable())
{
myDisposable.DoThing();
}
// not allowed, myDisposable is out of scope
//myDisposable.DoThing();
}
}
public class MyDisposable : IDisposable
{
public void DoThing()
{
// method intentionally left blank
}
public void Dispose()
{
Console.WriteLine("Disposed");
}
}
Assuming the standard description of the using statement, this is how lines 7-12 above are expanded by the compiler:
var myDisposable = new MyDisposable();
try
{
myDisposable.DoThing();
}
finally
{
if (myDisposable != null)
{
((IDisposable)myDisposable).Dispose();
}
}
// not allowed, myDisposable is out of scope
//myDisposable.DoThing();
However, the comment at line 13 is no longer correct; the variable myDisposable is now available in the whole method following its declaration.
Variable Scope
Assuming a variable is declared within the using statement, the compiler will scope that variable, by adding a set of braces around its usage. Here's the full method as it is compiled - note the braces at lines 3 and 16:
public static void Main(string[] args)
{
{
var myDisposable = new MyDisposable();
try
{
myDisposable.DoThing();
}
finally
{
if (myDisposable != null)
{
((IDisposable)myDisposable).Dispose();
}
}
}
// not allowed, myDisposable is out of scope
//myDisposable.DoThing();
}
Of course, it is possible to live more dangerously by applying the using statement on a variable declared outside scope of the using statement:
public static void Main(string[] args)
{
var myDisposable = new MyDisposable();
using (myDisposable)
{
myDisposable.DoThing();
}
// careful, myDisposable has been disposed
myDisposable.DoThing();
}
This is the second in what might soon be a series of blogposts on C# syntactic sugar - that is, where the language allows you to express your intent using a keyword, and the compiler restructures the code to perform how you expect it to.
The params Keyword
This post is about the params keyword. This keyword allows you to define an array parameter to a method, which can be specified by its caller as a list of values. Here's an example that demonstrates the flexible nature of the parameter:
public static void Main(string[] args)
{
// All valid calls
DoStuff();
DoStuff(1);
DoStuff(1, 2);
DoStuff(new[] { 1, 2 });
}
private static void DoStuff(params int[] ints)
{
// this method intentionally left blank
}
The IL
So, what does the compiler does with this? Here's the IL that the compiler produces for the DoStuff method, with the interesting bit highlighted:
Inspired by a talk I saw a DevWeek 2013 by Andrew Clymer, I took a look at the IL created by the C# compiler when the lock keyword is used. If you don't need an introduction to how the lock statement works, scroll down a bit and skip the first couple of C# snippets.
The Lock Statement
As a brief introduction to the lock keyword, it is used as a mechanism to allow access by a thread to a critical piece of code. Typically, this is when you have the possibility of multiple threads trampling on each other's data.
Take the sample code here:
using System;
using System.Threading;
using System.Threading.Tasks;
public class Program
{
public static void Main(string[] args)
{
// Create a totaliser
var totaliser = new Totaliser();
// Set it off on a new thread
Task.Run(() => totaliser.ModifyTotal());
// Give the totaliser a chance to do something
Thread.Sleep(100);
// Write the current total
Console.WriteLine(string.Format("Current value of Total: {0}", totaliser.Total));
Console.ReadLine();
}
}
public class Totaliser
{
public int Total { get; private set; }
// increment the total to 500, then down again to 0
public void ModifyTotal()
{
for (var counter = 0; counter < 5000000; ++counter)
{
Total++;
}
for (var counter = 0; counter < 5000000; ++counter)
{
Total--;
}
}
}
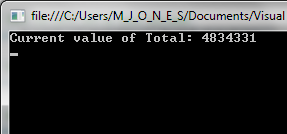
The intent of the Totaliser class is to be able to freely increment and decrement its Total without any external visibility of what's happening. Unfortunately, because its Total property is publicly readable, the Total can be read at any stage in the increment-decrement cycle in a multi-threaded environment:
A solution to this problem is to use the lock statement, around the reads and writes to Total:
using System;
using System.Threading;
using System.Threading.Tasks;
public class Program
{
public static void Main(string[] args)
{
// Create a totaliser
var totaliser = new Totaliser();
// Set it off on a new thread
Task.Run(() => totaliser.ModifyTotal());
// Give the totaliser a chance to do something
Thread.Sleep(100);
// Write the current total
Console.WriteLine(string.Format("Current value of Total: {0}", totaliser.Total));
Console.ReadLine();
}
}
public class Totaliser
{
private object lockObject = new object();
private int _total;
public int Total
{
get
{
lock (lockObject)
{
return _total;
}
}
private set { _total = value; }
}
// increment the total to 500, then down again to 0
public void ModifyTotal()
{
lock (lockObject)
{
for (var counter = 0; counter < 5000000; ++counter)
{
Total++;
}
for (var counter = 0; counter < 5000000; ++counter)
{
Total--;
}
}
}
}
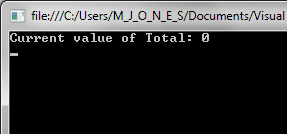
See the new lockObject at line 26, and the lock statement at lines 33 and 44.
The lock statement forces the thread to obtain a lock on the lockObject before it can proceed; if another thread has the lock, it must wait until it's been released. The result is a success:
The IL
Looking at the IL produced by the compiler, you can see the framework objects used to implement the lock:
The System.Threading.Monitor class has a couple of options when trying to grab a lock on an object, in particular the TryEnter method. This has an overload that takes a timeout value in milliseconds, which specifies how long this thread should wait to obtain the lock
I don't advocate rewriting your lock statements to use the longhand versions above, but this hopefully removes a layer of abstraction between you and your multi-threaded executable.